If you have been working in tech long enough it is unlikely you would not hear RESTful API. When I learn RESTful API for the first time I thought it would be easy, I mean why not? the technology has been around for more than 20 years, and it seems a pretty simple concept for resource-oriented web services. However, after doing some further reading I am started to doubt myself. When I trying to build my first RESTful API web services I realize it's actually really hard and the reason why is because there is no clear specification for REST. Yeah you heard me right, if you don’t believe me you can look on the internet and see that everyone pretty much has different opinion on the specification.
But why there are no clear specifications for REST? Because REST is actually an architectural set of guidelines, principles, and philosophies from Roy Fielding's thesis. Unlike JSON API or HAL, it’s not conedify into a set of steps or rules and we’re left to interpret his specification and different people interpret it differently.

In one of the online discussion forums, Roy Fielding recorded his frustration about a service that claims to be RESTful, but that service is a mere HTTP-based interface. He said the service was not fulfilling all the necessary REST architecture constraints. He even said that if the Engine of Application State (and hence the API) is not being driven by hypertext, then it cannot be RESTful and cannot be a REST API.

With that said, any services that need to be termed RESTful must strictly adhere to the mandatory REST architecture constraints. Those constraints are design rules that are applied to establish the distinct characteristics of the REST architectural style.
Building RESTful API may seem daunting, but if you follow the RESTful API Architecture Style Constraints rest assured it will set you on the right path and will help you develop high performance, scalability, simplicity, reliability, and maintainable RESTful API web services.
REST Concepts
The fundamental principle of REST is to use HTTP protocol for data communication between distributed hypermedia systems, and it revolves around the concept of resources where each and every component is considered as a resource, and those resources are accessed by common interfaces using HTTP methods.
REST is an architectural style and not a programming language or technology. It provides guidelines for distributed systems to communicate directly using the existing principles and protocols of the web to create web services and APIs
REST (Representational State Transfer) concepts were submitted as a PhD dissertation by Roy Fielding. As the founder of the REST style, he enforces the following 6 REST constraints as mandatory for any web service to be qualified as RESTful. These mandatory constraints are as follows.
REST Architectural Style Constraints
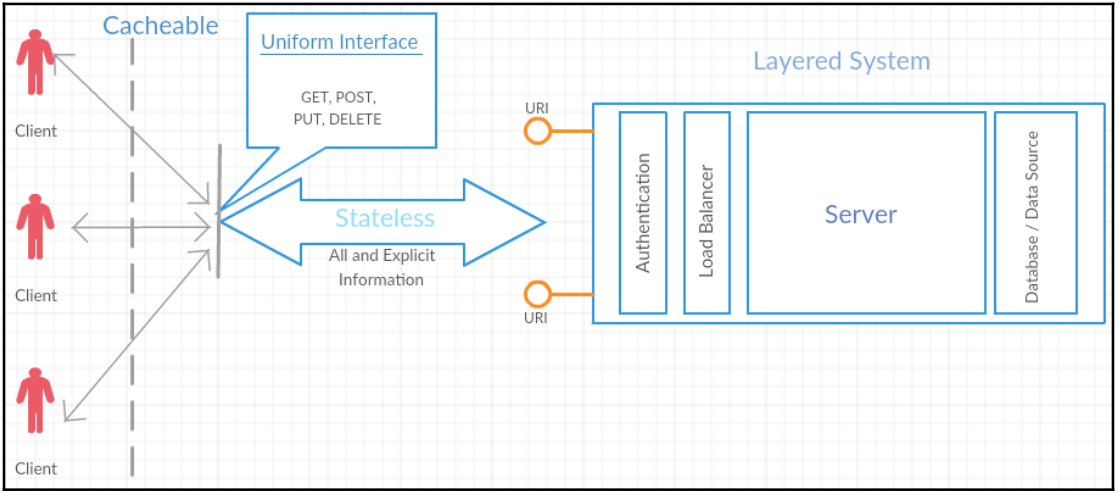
The following are the REST constraints:
- Client-server
- Statelessness
- Cacheable
- Uniform Interface
- Layered systems
- Code on demand (optional)
Client-server
The main purpose of client-server architecture is to help in the separation of concerns between the user interface and data storage. The client is acts as a requestor of services of the server, while the server act as the provider of services to the clients as per request.

First, there is no bound on the number of clients that can be serviced by a single server. It is also not mandatory that the client and server should reside in separate systems. Both can reside in the same system, based on the hardware configuration of the system and the type of functionality or service provided by the server.
The communication between client and server happens through the exchange of messages using a request-response pattern. The client basically sends a request for a service, and the server returns a response. For this communication to happen efficiently, it is necessary to have a well-defined communication protocol that lays down the rules of communication, such as the format of request messages, response messages, error handling, and so on. To further streamline the process of client-server communication, the server implements a specific API that can be used by the client for accessing any specific service from the server.
A server can receive requests from any number of clients at a specific point in time. But any server will have its own limitations about its processing capabilities. Often, it becomes necessary for a server to prioritize the incoming requests and service them as per their priority.
In addition to the separation of concern, having client-server architecture would have the following benefits
- Improve portability of user interface
- Improve scalability by simplifying server implementation
- Developing with standalone, independent, and testable component
Statelessness
Statelessness constraint help services to be more scalable and reliable. Statelessness in the REST context means that all the client requests to the server carry all the information as explicit (stated), so that the server understands the requests, treats them as independent, and those client requests keep the server independent of any stored contexts.

The statelessness constraint imposes significant restrictions on the kind of communications allowed between services and consumers, to achieves its design goals. The following are the restrictions to achieve statelessness.
- It is the complete responsibility of the client to store and handle all the application states and the related information on the client-side.
- The client is responsible for sending any state information to the server whenever it’s needed.
- No session stickiness or session affinity on the server for the calling request (client).
- The server also needs to include any necessary information that the client may need to create a state on its side.
- HTTP interactions involve two kinds of states, application state and resource state, and statelessness applies to both. Let’s see how the statelessness constraint is handled in each state:
- Application state: The data that is stored on the server side and helps to identify the incoming client request, using the previous interaction details with current context information
- Resource state: This is referred to as a resource representation, and it is independent of the client (the client doesn’t need to know this state unless it is available as response is needed), and this is the current state of the server at any given point in time
Advantages & disadvantages of statelessness
These are some advantages
- As the server does not need to manage any session, deploying the services to any number of servers is possible, and so scalability will never be a problem
- No states equals less complexity; no session (state) synchronize logic to handle at the server side
- As the service calls (requests) can be cached by the underlying application, the statelessness constraint brings down the server’s response time, that is, it improves performance with regard to response time
- Seamless integration/implementation with HTTP protocols is possible as HTTP is itself a stateless protocol
- Improves visibility as each request is its own resource and can be treated as an independent request
- Improves reliability as it can recover from partial failures
These are some disadvantages
- Increase per-interaction overhead
- Each request of webservices need to get additional information so that it get parsed (interpreted) so that the server understands the client state from incoming request and takes care of the client / server sessions if needed
Cacheable
Caching is the ability to store frequently accessed data (a response in this context) to serve the client requests, and never having to generate the same response more than once until it needs to be. Well-managed caching eliminates partial or complete client-server interactions and still serves the client with the expected response. Caching brings scalability and also performance benefits with faster response times and reduced server load.
As you can see in the diagram below, the client receives the response from the cache and not from the server itself, and a few other responses are directly from the server as well. So, caching help with the partial or complete elimination of some interactions between the service consumers and so helps to improve efficiency and performance (reduced latency time in response).

There are different caching strategies or mechanisms available, such as browser caches, proxy caches, and gateway caches (reverse-proxy), and there are several ways that we can control the cache behavior, such as through pragma, expiration tags, and so on. The table below gives a glimpse of the various cache-control headers one use to can finetune cache behaviors:

Benefit of caching
There are a lot of benefits to caching such as:
- Reduced bandwidth
- Reduced latency (faster response time)
- Reduced load on the server
- Hide network failures and serve a client with the response\
Uniform Interface
From all of the REST constraints, this is the most widely recognized and sometimes even misconceived as the RESTful itself. I believe most of you are familiar with this, yes this constraint is one that mentions the usage of HTTP methods like GET, POST, PUT, DELETE, and so on. However, the uniform interface is not solely about that, there are four important guiding principles suggested by Fielding that constitute the necessary constraints to satisfy the uniform interface, and they are as follows:
- Identification of resources
- Manipulation of resources
- Self-descriptive messages
- Hypermedia as the engine of application state (HATEOAS)
The main intention of a uniform interface is to retain some common vocabulary & uniformity across the internet. For example, GET does mean to get (read) something from the server. The services can independently evolve as their interfaces simplify and decouple the architecture, and the uniform interface brings a uniform vocabulary to those resources as well.
Identification of resources
In a web application, a Uniform Resource Identifier (URI) can represent a named entity. An entity can be identified and assigned as a resource by explicitly reference it. For example, an entity Project that belongs to an entity Organisationcan be identified in the following URI https://api.github.com/orgs/ORG/projects. In REST constraints, the URIs used are described as follows:
- The semantics mapping of the URI to a resource must not change. For example, Twitter’s https://api.twitter.com/1.1/statuses/retweets/:id as a URI may never change and will always represent retweets resources, even if the contents or values will keep improving, according to the latest updates.
- Resource identification is independent of its values so two resources could point to the same data at some point, but they are not the same resource
- URIs bring benefits such as only one way to access a resource, dynamic media types for resource responses (serve the media type at the time it is requested) with the help of the Accept headers, and clients accessing those dynamic resources do not need to change any identifiers if any change is made in the response content type.
Manipulation of resources
The concept of manipulation of resources is about clients ability to request different representations of the same resource. In this case, the application needs to support more than one representation of the same resource in the same URI when required.
The preceding concept is to allows the resource to be represented in different ways without changing its identifiers. It is possible with the HTTP header (Accept) getting passed to the server by the clients in each request. The resources are updated or added by sending representations from the client by the RESTful application. The following is a sample representation format, from Postman.

So, the decoupling of the resource’s representation from the URI is one of the crucial aspects of REST.
Self-descriptive messages
A client’s request and server’s response are messages and those messages should be stateless and self-descriptive. But what does it mean by stateless and self-descriptive?
A resource’s desired state can be represented within a client’s request message. And a resource’s current state may be embodied within the response message that comes back from a server. For example, a wiki page editor client may use a request message to transfer a representation that suggests a page update (new state) for a server-managed web page (resource).
Self-descriptive messages may include metadata to convey additional details regarding the resource state, the representation format and size, and even the message itself. An HTTP message provides headers for organizing the various types of metadata into uniform fields. The following image depicts a sample request and its headers, and the server response for the same request along with its headers.

So a self-descriptive message in REST style is all about not maintaining state between client and server, and each request needs to carry enough information about itself or explain with explicit states.
Hypermedia as the engine of application state (HATEOAS)
Hypermedia as the Engine of Application State (HATEOAS) is one of the most critical aspects of REST constraint. Without addressing it services cannot be termed RESTful services. But what is HATEOAS in the first place? Here is the main idea.
Once the client gets the initial response to its resource request from the server, it should be able to move to the next application state by picking up hyperlinks from the same received response.
With all that said the main idea of HATEOAS is for clients to use the hypermedia links provided in response. And allows the client to dynamically navigate to the appropriate resources by traversing the hypermedia links. The absence or presence of a link on a page is an essential part of the resource’s current state and so is essential for the RESTful APIs.
Please take a look at the following example.

In the preceding example, the response in right is provided with hyperlinks to “modify” and “delete” the resource. These links can be traversed by client to update or delete the mentioned resource. And through these hyperlinks, the server drives the application’s state and not the other way around.
Layered Systems
In general, a layered system consists of layers with different units of functionality. The essential characteristics of layered systems are that a Layer communicates by means of predefined interfaces and communicates only with the layer above or layer below, and the layers above rely on the layers below to it to perform its functions. Layers can be added, removed, modified, or reordered as the architecture evolves.

Let’s look at the following example. The REST style allows services to make use of a layered system architecture where we deploy the REST APIs on server A, store data on server B, and authenticate with server C. The client calling the REST API doesn’t have any knowledge of the servers the services use.

The REST architectural style suggests services can consist of multiple architectural layers. The layers will have published service contracts or intermediaries. The logic within a given layer cannot have knowledge beyond the immediate layers above or below it within the solution hierarchy.
While layered system brings additional latency and overhead, there are trade-offs that are benefits of layered system designs such as:
- Encapsulates legacy services
- Introduces intermediaries
- Limit system complexity
- Improves scalability
Code on Demand (optional)
Code on Demand is classified as optional, which means architectures that do not use this feature can still be considered RESTful.
In distributed computing, code on demand (COD) is any technology that enables the server to send the software code to the clients to be executed on the client computer upon request from the client’s software.
RESTful applications may very well be able to utilize clients that support COD. For instance, web browsers can allow servers to return scripts or links that can be executed at the client-side. This sort of additional code execution helps to expand the capabilities of the client, without needing the user to install new client software
Final Thought
Hey, you have reached the end of this long article. Thank you for reading until this point. As you have read above those are six REST constraints and how in Roy’s view they define an architectural style as RESTful.
Each constraint is a predetermined design decision and will have positive and negative influences on the services. However, these constraints are meant to provide a better architecture that resembles the web.
There may be a need for potential trade-offs when deviating from REST constraints. If you do so make sure those trade-offs don’t weaken or eliminate the mandated constraints. If so, that architecture may no longer conform to REST, or in other words, the services architecture is not RESTful.
The REST architectural style brings a set of properties that help to establish the design goals that are embedded in the application of REST constraints. These properties are as follows:
- Performance
- Scalability
- Simplicity
- Modifiability
- Visibility
- Portability
- Reliability
- Testability
The preceding properties signify a target state of software architecture and fundamental qualities of the WWW. Adhering to REST constraints in design decisions helps to achieve the preceding listed goals, and, of course, these properties can be further improved with more design decisions that are not necessarily parts of REST. However, a web service to be called a RESTful should adhere to the RESTful constraints.
I hope you enjoyed this article and found this story helpful, see you in the next story ✋